Нежное введение в ожидаемую стоимость, дисперсию и ковариацию с numpy
Содержание:
- Другие интересные функции Scipy
- Функции генерации псевдослучайных чисел
- отклонение
- Процедуры
- 7.5. Дискретное преобразование Фурье
- Compatibility notes
- Changed random variate stream from
- Scalar promotion in
- Fasttake and fastputmask slots are deprecated and NULL’ed
- casting behaviour with and
- Converting of empty array-like objects to NumPy arrays
- Removed
- has been removed
- no longer interprets as
- Change output of on scalars to be consistent with Python
- The constructor no longer interprets as
- C-Level string to datetime casts changed
- 7.1.1. Значения -inf, inf и nan
- Практическое задание NumPy
Другие интересные функции Scipy
Во-первых, если у вас нет соответствующей теоретической подготовки, то выполнение их в Scipy не имеет большого смысла. Во-вторых, они используются не слишком часто, лишь при необходимости, так что на самом деле нет особой необходимости испытывать их, пока не появится нужда в них. Цель этой лекции – рассказать об их существовании и где их найти, а также подчеркнуть, что это не слишком сложно и что вам не нужен ещё кто-то, чтобы показать, как пользоваться этими функциями. Если вы освоили остальную часть этого курса, то у вас не должно возникнуть проблем с самостоятельным их освоением, они должны работать, как предусмотрено.
Итак, первой мы рассмотрим функцию loadmat. В академических кругах MATLAB является очень популярным компьютерным языком для вычислений, с которым вы периодически будете сталкиваться, а если учитесь, то, наверное, уже сталкивались. В MATLAB есть собственный формат файлов – .mat; он не является текстовым, поэтому его нельзя просто прочитать строка за строкой. Данная функция Scipy позволяет корректно открывать и работать с этими файлами, если у вас появится необходимость работать с данными, хранящимися в формате MAT.
В дополнение к изображениям существует другой распространённый источник «физических» данных – аудио. Аудио – это звук, а звук, в простейшем формате, хранится в WAV-файлах. Данные файлы содержат амплитуду сигнала в каждый момент времени; обычно частота дискретизации составляет 44,1 килогерц, что значит, что в каждую секунду имеется 44100 целых чисел, представляющих звук. Эти файлы можно считывать с помощью функции scipy.io.wavfile.read и записывать с помощью функции scipy.io.wavfile.write.
Очень тесно с машинным обучением связана обработка сигналов. Одной из популярнейших функций для этого является свёртка. Если вы слышали о свёрточных нейронных сетях, то как раз в них этот метод и работает. В Scipy есть несколько функций для свёртки. Функция scipy.signal.convolve используется для любых сигналов любого размера, а для изображений, являющихся двухмерными массивами (если они чёрно-белые), можно использовать scipy.signal.convolve2d.
Кроме того, в модуле signal есть ряд интересных функций для создания фильтров. Фильтры – это, по сути, формы колебаний, тем или иным образом изменяющие входной сигнал, например ревербация, эффект эха и так далее. Но, как ни странно, преобразование Фурье, являющееся одной из наиболее распространённых функций обработки сигналов, содержится не в Scipy, а в Numpy, так что воспользоваться ею можно, даже не будучи знакомым с библиотекой Scipy. Преобразование Фурье преобразует сигнал из временной области в частотную. Другими словами, оно показывает частотные составляющие исходного сигнала.
В качестве примера создадим синусоиду с несколькими частотами и выведем её на экран, чтобы вы знали, как всё это выглядит:
x = np.linspace(0, 100, 1000)
y = np.sin(x) + np.sin(3*x) + np.sin(5*x)
plt.plot(y)
plt.show()
Вот она – периодическая волна с несколькими частотными составляющими. Теперь сделаем быстрое преобразование Фурье. Не забывайте, что преобразование даёт нам сигнал с комплексными числами, поэтому прежде, чем отображать его, необходимо найти модуль:
Y = np.fft.fft(y)
plt.plot(np.abs(Y))
plt.show()
И получаем преобразование Фурье. Если увеличить изображение, то можно увидеть пики, представляющие исходные частотные компоненты. Так, мы видим пики в районе 80, 48 и 16. Закроем этот график и рассчитаем, какие частоты они представляют:
2*np.pi*16/100
Это даёт 1.
2*np.pi*48/100
Это даёт 3.
2*np.pi*80/100
И это даёт нам 5.
Это и есть оригинальные частоты. Не переживайте особо, если не понимаете, что это значит, – я лишь хотел показать возможности инструментария Numpy.
Post Views: 1 999
Мне нравитсяНе нравится
Функции генерации псевдослучайных чисел
|
Название |
Описание |
|
random.rand() |
Генерация |
|
np.random.randint() |
Генерация |
|
np.random.randn() |
Генерация |
|
np.random.seed() |
Установка |
Во многих
программах требуется генерировать случайные значения и в NumPy для этого
имеется специальный модуль random с богатым функционалом. Конечно,
совершенно случайные величины получить невозможно, поэтому придумываются
различные «хитрости» для их генерации и правильнее их называть –
псевдослучанйыми числами.
В самом простом
случае, функция rand() позволяет получать случайные числа в диапазоне от
0 до 1:
np.random.rand() # вещественное случайное число от 0 до 1
Если требуется
получить массив из таких чисел, то можно указать это через первый аргумент:
np.random.rand(5) # array()
Для получения
двумерных массивов – два аргумента:
np.random.rand(2, 3) # массив 2x3
И так далее.
Можно создавать любые многомерные массивы из случайных величин.
Если требуется
генерировать целые случайные значения, то используется функция randint():
np.random.randint(10) # генерация целых чисел в диапазоне [0; 10) np.random.randint(5, 10)# генерация в диапазоне [5; 10)
Для получения
массива из таких случайных чисел дополнительно следует указать параметр size, следующим
образом:
np.random.randint(5, size=4) # array() np.random.randint(1, 10, size=(2, 5)) # матрица 2x5
Функции rand() и randint() генерируют
числа с равномерным законом распределения. Если нужно получать значения с
другими широко известными распределениями, то используются функции:
np.random.randn() # нормальная СВ с нулевым средним и единичной дисперсией np.random.randn(5) # массив из пяти нормальных СВ np.random.randn(2, 3) # матрица 2x3 из нормальных СВ np.random.pareto(2.0, size=3) # распределение Паретто с параметром 2,0 np.random.beta(0.1, 0.3, size=(3, 3)) # бета-распределение с параметрами 0,1 и 0,3
Существуют и
другие функции для генерации самых разных распределений. Документацию по ним
можно посмотреть на официальном сайте пакета NumPy:
По умолчанию,
все рассмотренные функции при каждом новом запуске генерируют разные числа.
Однако, иногда требуются одни и те же их реализации. Например, такой подход
часто используется для сохранения начальных случайных значений весов в
нейронных сетях. Для этого устанавливают некое начальное значение зерна (seed):
np.random.seed(13) # начальное значение генератора случайных чисел
и все
последующие запуски будут давать одну и ту же последовательность чисел,
например:
np.random.randint(10, size=10) # array()
Причем, у вас
должны получиться такие же числа. Если запустим эту функцию еще раз, то будут
получены следующие 10 случайных чисел:
np.random.randint(10, size=10) # array()
Но, установив
зерно снова в значение, например, 13:
np.random.seed(13)
числа начнут
повторяться:
np.random.randint(10, size=10) # array() np.random.randint(10, size=10) # array()
отклонение
По вероятности, дисперсия некоторой случайной величины X является мерой того, насколько значения в распределении варьируются в среднем по отношению к среднему.
Дисперсия обозначается как функция Var () для переменной.
Дисперсия рассчитывается как среднеквадратическая разница каждого значения в распределении от ожидаемого значения. Или ожидаемое квадратичное отличие от ожидаемого значения.
Предполагая, что ожидаемое значение переменной было вычислено (E ), дисперсия случайной величины может быть рассчитана как сумма квадратов разности каждого примера от ожидаемого значения, умноженного на вероятность этого значения.
Если вероятность каждого примера в распределении равна, вычисление дисперсии может отбросить отдельные вероятности и умножить сумму квадратов разностей на обратную величину количества примеров в распределении.
В статистике дисперсию можно оценить из выборки примеров, взятых из домена.
В реферате выборочная дисперсия обозначается сигмой в нижнем регистре с 2 верхними индексами, указывающими, что единицы возведены в квадрат, а не то, что вы должны возвести в квадрат окончательное значение. Сумма квадратов разностей умножается на обратную величину количества примеров минус 1, чтобы скорректировать смещение.
В NumPy дисперсию можно рассчитать для вектора или матрицы с помощью функции var (). По умолчанию функция var () вычисляет дисперсию населения. Чтобы вычислить выборочную дисперсию, вы должны установить аргумент ddof в значение 1.
В приведенном ниже примере определяется 6-элементный вектор и вычисляется выборочная дисперсия.
При выполнении примера сначала печатается определенный вектор, а затем вычисленная выборочная дисперсия значений в векторе
Функция var может вычислить дисперсию строки или столбца матрицы, указав аргумент оси и значение 0 или 1 соответственно, то же самое, что и средняя функция выше.
В приведенном ниже примере определяется матрица 2 × 6 и рассчитывается выборочная дисперсия столбца и строки.
При выполнении примера сначала печатается определенная матрица, а затем значения дисперсии выборки столбца и строки.
Стандартное отклонение рассчитывается как квадратный корень из дисперсии и обозначается строчными буквами «s».
Чтобы придерживаться этого обозначения, иногда дисперсия обозначается как s ^ 2, где 2 — верхний индекс, снова показывая, что единицы возведены в квадрат.
NumPy также предоставляет функцию для вычисления стандартного отклонения напрямую через функцию std (). Как и в случае функции var (), аргумент ddof должен быть установлен в 1 для расчета стандартного отклонения несмещенной выборки, а стандартные отклонения столбца и строки можно рассчитать, установив аргумент оси в 0 и 1 соответственно.
В приведенном ниже примере показано, как рассчитать стандартное отклонение выборки для строк и столбцов матрицы.
При выполнении примера сначала печатается определенная матрица, а затем значения стандартного отклонения выборки столбца и строки.
Процедуры
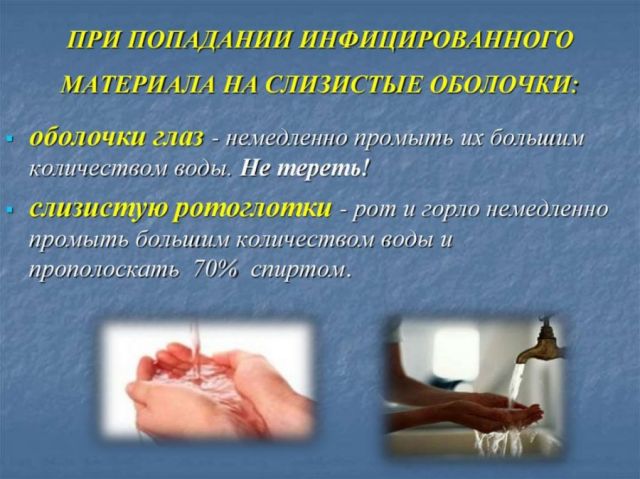
Для мониторинга вирусной нагрузки всем пациентам было предложено произвести ранний утренний сбор отделяемого с задней стенки ротоглотки (то есть откашляться путем прочистки горла) перед чисткой зубов и завтраком, потому что выделения из носоглотки перемещаются кзади, а бронхолегочные выделения перемещаются при помощи цилиарной активности в заднюю ротоглоточную область при нахождении пациентов в положении лежа на спине во время сна. Пациенты были проинструктированы и контролировались медсестрами. Вирусную транспортную среду добавляли к образцу слюны. Если пациенты были интубированы, мы получали эндотрахеальный аспират вместо слизи с задней стенки ротоглотки. Наш первоначальный опыт показал, что такие образцы являются перспективными для мониторинга вирусной нагрузки у пациентов с COVID-19. Мы также получили остатки сыворотки крови от образцов крови, взятых для рутинных биохимических исследований, и охладили эти образцы до –20 °C до проведения анализа на антитела.
Клинические данные были внесены в предварительно разработанную базу данных, включающую историю болезни и физическое обследование пациента, а также результаты гематологических, биохимических, рентгенологических и микробиологических исследований. Тяжелая форма заболевания определялась в случае потребности в дополнительном кислороде, поступления в отделение интенсивной терапии (ICU) или смерти.
Проведена внутренняя количественная ПЦР с обратной транскрипцией (ОT-кПЦР), нацеленная на область гена РНК-зависимой РНК-полимеразы-хеликазы SARS-CoV-2. Также выполнен ИФА на нуклеопротеин SARS-CoV-2 (NP) и рецептор-связывающий домен шиповидных белков (RBD), как описано, но с модификациями. Рекомбинантный нуклеопротеин (NP) и рецептор-связывающий домен шиповидных белков (RBD) SARS-CoV-2 использовали для ИФА.
Оценена чистота NP и RBD методом электрофореза в полиакриламидном геле в присутствии додецилсульфата натрия, а также вестерн-блоттингом (рис. 1A, B). Положительный образец был включен в каждый прогон в качестве положительного контроля. В качестве отрицательного контроля использовался архивный анонимный образец 2018 года. В качестве порогового уровня серопозитивности было установлено среднее значение для 93 анонимных архивных образцов сыворотки 2018 года плюс 3 стандартных отклонения. Мы проверили достоверность ИФА с помощью конкурентного ИФА и вестерн-блоттинга, используя образцы сыворотки пациентов (рис. 1C, D).
Проведена реакция микронейтрализации и культивирование вируса. Также проведено полногеномное секвенирование с использованием анализатора Oxford Nanopore MinION (Oxford Nanopore Technologies, Oxford, UK).
Рисунок 1 | ИФА с использованием рекомбинантного нуклеопротеина (NP) и рецептор-связывающего домена шиповидных белков (RBD) SARS-CoV-2
(A) Электрофорез в полиакриламидном геле в присутствии додецилсульфата натрия показывает чистоту His-меченого (полигистидин-меченого) рецептор-связывающего домена (RBD) шиповидных белков (трек 1) и His-меченого NP (трек 3). Трек 2 — маркер молекулярной массы белка. Вестерн-блоттинг рецептор-связывающего домена (RBD) шиповидных белков (трек 1) и нуклеопротеина (NP) (трек 2) с использованием моноклональных анти-His антител. Положительный контроль (нуклеопротеин вируса острой лихорадки с тромбоцитопеническим синдромом) в треке №3 и отрицательный контроль (GST-меченый белок) в треке 4 (С). Подтверждающее исследование вестерн-блот нуклеопротеина (NP) с использованием сыворотки пациента. Моноклональные анти-Нis антитела в треке 1, сыворотка неинфицированного пациента в треке 2, образцы сыворотки пациента с COVID-19, взятые в острую фазу заболевания (5 дней после появления симптомов) в треке 3 (титр 1 к 100 ), и на протяжении периода выздоровления (18 дней после появления симптомов) в треке 4 (титр 1 к 3200), трек 5 (1 к 1600) и трек 6 (1 к 8000). (D) Подтверждающий вестерн-блот рецептор-связывающего домена (RBD) шиповидных белков с использованием образцов сыворотки от пациентов с COVID-19. Моноклональные анти-His антитела в треке 1, сыворотка неинфицированного пациента в треке 2, сыворотка двух пациентов с COVID-19 в треках 3 и 4 (титр 1 к 100).NP — нуклеопротеинRBD — рецептор-связывающий доменHis — полигистидин GST — глютатион-S-трансферазаCOVID-19 — коронавирусная болезнь 2019
7.5. Дискретное преобразование Фурье
Если данные в ваших массивах — это сигналы: звуки, изображения, радиоволны, котировки акций и т.д., то вам наверняка понадобится дискретное преобразование Фурье. В NumPy представлены методы быстрого дискретного преобразования Фурье для одномерных, двумерных и многомерных сигналов, а так же некоторые вспомогательные функции. Рассмотрим некоторые простые примеры.
Одномерное дискретное преобразование Фурье:
Двумерное дискретное преобразование Фурье:
Очень часто при спектральном анализе используются оконные функции (оконное преобразование Фурье), некоторые из которых так же представлены в NumPy
Compatibility notes
Changed random variate stream from
A bug in the generation of random variates for the Dirichlet
distribution with small ‘alpha’ values was fixed by using a different
algorithm when . Because of the change, the stream of
variates generated by in this case will be different from
previous releases.
(gh-14924)
Scalar promotion in
The promotion of mixed scalars and arrays in has been changed to adhere to those used
by . This means that input such as will now return
dtypes. In most cases the behaviour is unchanged. Note that the use of
this C-API function is generally discouraged. This also fixes to behave the same way as the rest of NumPy in this respect.
(gh-14933)
Fasttake and fastputmask slots are deprecated and NULL’ed
The fasttake and fastputmask slots are now never used and must always be
set to NULL. This will result in no change in behaviour. However, if a
user dtype should set one of these a DeprecationWarning will be given.
(gh-14942)
casting behaviour with and
now uses the casting rule for its additional and arguments. This ensures type safety except when
the input array has a smaller integer type than or .
In rare cases, the behaviour will be more strict than it was previously
in 1.16 and 1.17. This is necessary to solve issues with floating point
NaN.
(gh-14981)
Converting of empty array-like objects to NumPy arrays
Objects with which implement an «array-like»
interface, meaning an object implementing ,, , or the python buffer
interface and which are also sequences (i.e. Pandas objects) will now
always retain there shape correctly when converted to an array. If such
an object has a shape of previously, it could be converted into
an array of shape (losing all dimensions after the first 0).
(gh-14995)
Removed
As part of the continued removal of Python 2 compatibility, was removed. On Python 3, it threw a and was unused internally. It is expected that
there are no downstream use cases for this method with Python 3.
(gh-15229)
has been removed
This module contained only the function , which was
used as:
Its purpose was to handle the change in syntax introduced in Python 2.6,
from to , meaning it was
only necessary for codebases supporting Python 2.5 and older.
(gh-15255)
no longer interprets as
had a FutureWarning since NumPy 1.14 which has
expired now. This means that certain input where the second argument was
neither a datatype nor a NumPy scalar type (such as a string or a python
type like or ) will now be consistent with passing in. This makes the result consistent with
expectations and leads to a false result in some cases which previously
returned true.
(gh-15773)
Change output of on scalars to be consistent with Python
Output of the dunder method and consequently the Python
built-in has been changed to be a Python to be consistent
with calling it on Python objects when called with no arguments.
Previously, it would return a scalar of the that was passed
in.
(gh-15840)
The constructor no longer interprets as
The former has changed to have the expected meaning of setting to , while the latter continues to result in
strides being chosen automatically.
(gh-15882)
C-Level string to datetime casts changed
The C-level casts from strings were simplified. This changed also fixes
string to datetime and timedelta casts to behave correctly (i.e. like
Python casts using while previously the cast
would behave like . This only
affects code using low-level C-API to do manual casts (not full array
casts) of single scalar values or using e.g. , and
should thus not affect the vast majority of users.
(gh-16068)
7.1.1. Значения -inf, inf и nan
Возможно вы обратили внимание на то, что когда мы вычисляли натуральный логарифм массива, среди значений которого был ноль, не появилось абсолютно никакой ошибки, а сам логарифм стал равен значению (минус бесконечность). Убедимся в этом еще раз:. Более того, в NumPy мы даже можем делить на ноль:
Более того, в NumPy мы даже можем делить на ноль:
NumPy предупредил нас о том, что встретил деление на ноль, но тем не менее выдал ответ (плюс бесконечность). Дело в том, что с математической точки зрения все абсолютно верно — если вы что-то делите на бесконечно малое значение то в результате получете значение, которое окажется бесконечно большим. Если результатом математической операции является плюс или минус бесконечность, то логичнее выдать значение или чем выдавать ошибку.
В NumPy есть еще одно специальное значение — . Данное значение выдается тогда, когда результат вычислений не удается определить:
Заметьте, что NumPy нас просто предупредил о том, что ему попалось недопустимое значение, но ошибки не возникло. Дело в том, что в реальных вычислениях значения , или встречается очень часто, поэтому появление этого значения проще обрабатывать специальными методами (функции и ), чем постоянно лицезреть сообщения об ошибках.
Новичкам, довольно трудно привыкнуть, к тому что в недрах компьютера вся арифметика на самом деле является двоичной и с этим связано очень много казусов. Во первых не совсем понятно, когда ждать появления значений и :
Число 1.633123935319537e+16 появилось потому что в NumPy выполняются арифметические, а не символьные вычисления, т. е. число π хранится в памяти компьютера не как знание о том, что это математическая константа с бесконечным количеством десятичных знаков после запятой, а как обычное число с десятичной точкой (десятичная дробь) равная числу π с очень маленькой, но все же, погрешностью:
NumPy отличает предельные случаи, когда вычисления выполнить невозможно, например, деление на ноль. В таких случаях появляются значения , и . Если из-за самых незначительных погрешностей вычисления все же возможны, то NumPy их обязательно выполнит. В этих случаях вместо значений или у вас будут появляться самые маленькие или самые большие числа, которые возможно представить на вашем компьютере.
Тем не менее и на этом сюрпризы не заканчиваются. Если число 1.633123935319537e+16 является самым больши, которое может появиться при вычислениях, оно вполне ожидаемо должно появиться в самых разных ситуациях. Например:
То, есть какая-то, длинная арифметика все же доступна — очень хорошая новость, для лбителей криптографии и теории чисел. Но иногда:
В заключение могу лишь сказать, что все предельные случаи требуют кардинальных решений. Некоторые решения имеются в самом NumPy, некоторые предоставляют другие пакеты. Если вам необходимы точные решения, то лучше обратиться к системам компьютерной алгебры и символьных вычислений, например пакету SymPy — маленький, но мощьный пакет Python для символьных вычислений. Если вы решили отправиться в самые дебри теории чисел, алгебры и криптографии, то лучшим решением окажется программа GAP. Программа GAP не является программой Python, но имеет Python интерфейс в замечательной программе Sage, которая определенно заслуживает вашего внмания.
Практическое задание NumPy
Задание 1
- Импортируйте библиотеку Numpy и дайте ей псевдоним np.
Создать одномерный массив Numpy под названием a из 12 последовательных целых чисел чисел от 12 до 24 невключительно
Создать 5 двумерных массивов разной формы из массива a. Не использовать в аргументах метода reshape число -1.
Создать 5 двумерных массивов разной формы из массива a.
Использовать в аргументах метода reshape число -1 (в трех примерах — для обозначения числа столбцов, в двух — для строк).
Можно ли массив Numpy, состоящий из одного столбца и 12 строк, назвать одномерным? - Создать массив из 3 строк и 4 столбцов, состоящий из случайных чисел с плавающей запятой из нормального распределения со средним, равным 0 и среднеквадратичным отклонением, равным 1.0.
Получить из этого массива одномерный массив с таким же атрибутом size, как и исходный массив. - Создать массив a, состоящий из целых чисел, убывающих от 20 до 0 невключительно с интервалом 2.
Создать массив b, состоящий из 1 строки и 10 столбцов: целых чисел, убывающих от 20 до 1 невключительно с интервалом 2.
В чем разница между массивами a и b? - Вертикально соединить массивы a и b. a — двумерный массив из нулей, число строк которого больше 1 и на 1 меньше, чем число строк двумерного массива b, состоящего из единиц. Итоговый массив v должен иметь атрибут size, равный 10.
- Создать одномерный массив а, состоящий из последовательности целых чисел от 0 до 12.
Поменять форму этого массива, чтобы получилась матрица A (двумерный массив Numpy), состоящая из 4 строк и 3 столбцов.
Получить матрицу At путем транспонирования матрицы A.
Получить матрицу B, умножив матрицу A на матрицу At с помощью матричного умножения.
Какой размер имеет матрица B? Получится ли вычислить обратную матрицу для матрицы B и почему? - Инициализируйте генератор случайных числе с помощью объекта seed, равного 42.
Создайте одномерный массив c, составленный из последовательности 16-ти случайных равномерно распределенных целых чисел от 0 до 16 невключительно.
Поменяйте его форму так, чтобы получилась квадратная матрица C.
Получите матрицу D, поэлементно прибавив матрицу B из предыдущего вопроса к матрице C, умноженной на 10.
Вычислите определитель, ранг и обратную матрицу D_inv для D. - Приравняйте к нулю отрицательные числа в матрице D_inv, а положительные — к единице. Убедитесь, что в матрице D_inv остались только нули и единицы.
С помощью функции numpy.where, используя матрицу D_inv в качестве маски, а матрицы B и C — в качестве источников данных, получите матрицу E размером 4×4.
Элементы матрицы E, для которых соответствующий элемент матрицы D_inv равен 1, должны быть равны соответствующему элементу матрицы B, а элементы матрицы E, для которых соответствующий элемент матрицы D_inv равен 0, должны быть равны соответствующему элементу матрицы C.
Задание 2
Создайте массив Numpy под названием a размером 5×2, то есть состоящий из 5 строк и 2 столбцов.
Первый столбец должен содержать числа 1, 2, 3, 3, 1, а второй — числа 6, 8, 11, 10, 7.
Будем считать, что каждый столбец — это признак, а строка — наблюдение.
Затем найдите среднее значение по каждому признаку, используя метод mean массива Numpy.
Результат запишите в массив mean_a, в нем должно быть 2 элемента.
Задание 3
Вычислите массив a_centered, отняв от значений массива а средние значения соответствующих признаков, содержащиеся в массиве mean_a.
Вычисление должно производиться в одно действие.
Получившийся массив должен иметь размер 5×2.
Задание 4
Найдите скалярное произведение столбцов массива a_centered.
В результате должна получиться величина a_centered_sp.
Затем поделите a_centered_sp на N-1, где N — число наблюдений.
Задание 5**
Число, которое мы получили в конце задания 3 является ковариацией двух признаков, содержащихся в массиве а. В задании 4 мы делили сумму произведений центрированных признаков на N-1, а не на N, поэтому полученная нами величина является несмещенной оценкой ковариации.
В этом задании проверьте получившееся число, вычислив ковариацию еще одним способом — с помощью функции np.cov.
В качестве аргумента m функция np.cov должна принимать транспонированный массив a.
В получившейся ковариационной матрице (массив Numpy размером 2×2) искомое значение
ковариации будет равно элементу в строке с индексом 0 и столбце с индексом 1.