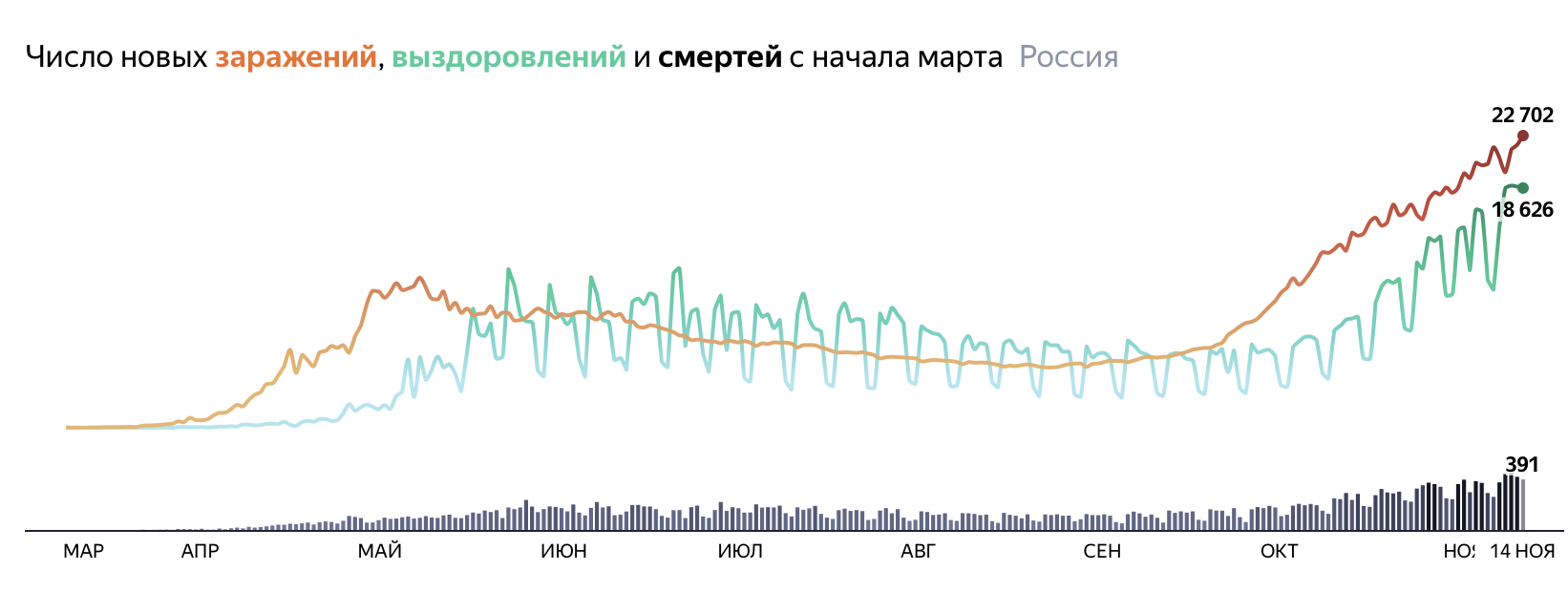
О прогнозировании распространения covid-19
Содержание:
Иллюзия информированности
«Яндекс.Карты» публикуют «Индекс Самоизоляции», а Apple и Google анонсировали проект по отслеживанию передвижений в условиях пандемии коронавируса — уже сейчас на сайте Apple и Google доступен датасет по перемещениям по основным городам мира. Эти разработки призваны помочь в мониторинге изоляции, социального дистанцирования и отслеживания контактов с инфицированными. Data-журналисты из крупных СМИ — Reuters, New York Times, FT, The Guardian — публикуют большое количество инфографики с динамикой роста смертей и зараженных.
Насколько полезна эта информация? Выглядит она красиво и занимательно, но мало о чем говорит и не отражает реальной картины эпидемиологической ситуации ни в одной стране мира.
«Индекс Самоизоляции» «Яндекса» и передвижения Apple и Google исправно показывают, как часто люди идут в магазин и курьер объезжает клиентов. Но эти технологии ничего не говорят нам о том, надевают ли люди маску, соблюдают ли социальную дистанцию и есть ли у них легкие симптомы заболевания. Количество зараженных врачей, сотрудников полиции и магазинов говорит о том, что даже среди этих категорий повышенного риска меры и средства индивидуальной защиты применяются недостаточно.
Отслеживание геолокации с помощью персональных мобильных устройств слабо коррелирует с вероятностью заражения. Представим себе 20-этажный жилой дом в центре города, где на разных этажах находится более 50 человек с абсолютно одинаковой геолокацией. Вошли ли они в контакт с зараженным человеком, который остановился на пару минут под их окнами, чтобы ответить на телефонный звонок?
Фото: Jack Robinson / Unsplash
В 1919 году по следам «испанки», самой разрушительной пандемии 20-го века, в журнале Science Дж. Сопер отметил три фактора, препятствующих ее предотвращению:
- общественное равнодушие, вызванное непониманием риска;
- противоестественность заключения себя в жесткую изоляцию для защиты других;
- неосознанное заражение других людьми без проявления симптомов.
Для анализа и прогнозирования пандемического процесса сегодня, как и 100 лет назад, необходимо понимание не только эпидемиологии, но и социальной психологии. Именно из-за разницы в социальных процессах мы наблюдаем часто диаметрально противоположные тенденции распространения эпидемии в разных обществах в мире. Эксперты в эпидемиологии и социальной психологии могут выработать эффективные гипотезы, которые смогут проверить data scientists с помощью аналитики на больших данных
Например, мы четко понимаем, что критически важно замерять уровень общественной паники и уровень соблюдения мер предосторожности
«Если мы говорим именно о панике, то замерить ее через анализ социальных сетей и СМИ «в моменте» качественно нельзя. Это связано с тем, что гипотеза о том, имеем мы дело с паникой или всплеском какой-то краткосрочной реакции, проверяется на отрезке времени более чем сутки. Во-вторых, паника — это не только слова, картинки, или заявления комментаторов в СМИ определенной тональности. Это действия. Здесь требуется параллельная фиксация поведения или шагов (например, скупка продуктов питания или туалетной бумаги), что опять-таки требует работы с временными отрезками, а не «в моменте», — утверждает Петр Кирьян, директор по медиапроектам КРОС и автор исследования .
Использование анализа больших массивов контента социальных сетей для выявления источников эпидемиологического риска не является новой идеей. Алгоритмы ИИ применяются в таких решениях для того, чтобы отфильтровать побочные инфошумы и выявить сигналы о фактических вспышках заболеваний. Параллельно с помощью спутниковых данных анализируют климатические условия. Например, канадская компания BlueDot сотрудничает с правительствами Канады, Сингапура, Калифорнии, Великобритании и Филиппин по выявлению и оценке эпидемиологических рисков с 2012 года. Она стала одной из первых компаний, предупредивших о возникновении нового вируса в Ухани.
Фото: angellodeco / Shutterstock
В ожидании пика
По подсчетам исследователей, два крупнейших города страны уже приблизились ко второму с начала эпидемии пику по количеству активных случаев болезни. В Москве ученые ожидают его 10–12 декабря, в Петербурге — 15–16 декабря. В столице на пике количество одновременно болеющих, согласно расчетам ученых, составит 149–151 тыс. человек, а в городе на Неве — 64–65 тыс. Эти значения необходимо учитывать, чтобы понимать уровень загрузки системы здравоохранения и планировать ее работу на перспективу, отмечают авторы методики.
В целом по России, говорится в отчете Центра интеллектуальной логистики СПбГУ, ежедневный прирост новых случаев заболеваний в течение последних двух недель колеблется в диапазоне 24–27 тыс. При этом 3 декабря этот показатель впервые превысил 28 тыс. человек. Если такой уровень прироста сохранится в течение 7–10 дней (то есть РФ окажется на плато по показателю новых заражений) и в дальнейшем начнет уменьшаться, 22 декабря страна может выйти на пик по количеству активных случаев с числом болеющих в диапазоне 514–517 тыс., полагают ученые. 6 декабря этот показатель находился на отметке 479,8 тыс. человек.
Математика пандемии
Фото: ИЗВЕСТИЯ/Константин Кокошкин
Новая модель CBRR построена на итеративном подходе: данные, на основании которых строятся прогнозы на 2–3 недели, обновляются в реальном времени. Таким образом, течение эпидемии за последний анализируемый временной промежуток дает возможность более точно рассчитать прогноз ее развития в ближайшем будущем.
— Важная составляющая итеративной процедуры — формирование цепочки ESC (Epidemic Spreading Chain) стран распространения эпидемии, — объясняет Виктор Захаров. — Это цепочка включает в себя несколько стран, упорядоченных по времени выхода их на одинаковые уровни значения выбранных параметров. Страна, для которой строится прогноз, называется страной-последователем (Country Follower), остальные — странами-предшественниками (Country Predecessor).
Исследователь отметил, что для верной настройки модели необходимо, чтобы в странах ESC использовались сравнительно одинаковые меры сдерживания эпидемии: карантин, самоизоляция, социальная дистанция и т.п.
Как уточнил Виктор Захаров, эпидемия в России — в данном случае стране-последователе — характеризуется более поздним по сравнению с другими странами моментом достижения процентного прироста одних и тех же значений. Поэтому в цепочку ESC при моделировании и прогнозировании динамики эпидемии в России в качестве предшественников включили Италию, Испанию, Великобританию и Францию.
Математика пандемии
Фото: ИЗВЕСТИЯ/Сергей Коньков
— Нам нужны были страны с примерно похожими противоэпидемическими мерами, в которых динамические показатели, характеризующие течение эпидемии, появлялись бы раньше минимум на три недели или месяц, — объясняет Виктор Захаров. — Поэтому мы, например, не взяли Германию — она очень близка к нам по времени развития пандемии. Не взяли и Китай, меры в котором несопоставимы с нашими.
Последовательно сгенерированная на основании сделанного выбора траектория эволюции статистических данных об эпидемии (в частности, общего количества инфицированных людей) сравнивается с фактической статистикой — таким образом получается довольно точный, но недолговременный прогноз с горизонтом 2–3 недели.
Разработчики симулятора
Обильное наличие изменяющихся переменных требуют вычислительных мощностей и частых расчетов, а для точности прогнозов использование машинного обучения и навыков работы с ИИ.
Модель SEIR подробно описал Леонид Жуков, кандидат наук, профессор кафедры анализа данных и искусственного интеллекта, кафедра информатики Национального исследовательского университета «Высшая школа экономики». В прошлом – старший научный сотрудник Калифорнийского технологического института, работал в компании Yahoo:
- https://www.researchgate.net/profile/Leonid_Zhukov
- https://www.hse.ru/en/staff/lzhukov
- https://scholar.google.ru/citations?hl=ru&user=1DnNa84AAAAJ
Разработчик и автор прогнозов Youyang Gu (см. Вики), независимый исследователь данных. Youyang бакалавр Массачусетского технологического института (MIT) по специальности Electrical Engineering & Computer Science and Mathematics. Получил степень магистра, защитив диссертацию по обработке естественного языка в Лаборатории компьютерных наук и искусственного интеллекта Массачусетского технологического института.
Математическая модель распространения эпидемии
Распространение эпидемий происходит по математическому закону SIR (Susceptible – подверженные заражению люди, Infectious – инфицированные, Recovered — вылечившиеся), разработанный в 20х годах прошлого столетия.
Модель предсказывает распространение болезни, общее число инфицированных, продолжительность эпидемии, оценивает различные эпидемиологические параметры, например, репродуктивное число R0. Модель показывает, как различные меры общественного здравоохранения влияют на исход эпидемии, каков наиболее эффективный метод для выпуска ограниченного числа вакцин в данной популяции и т.д.
Базовая SIR-модель и её продвинутые версии единственные практические модели, способные строить наиболее точные прогнозы. Подробнее на Вики.
SIR применима ко многим болезням: кори, паротиту (свинка), краснухе, которые являются воздушно-капельными детскими болезнями с пожизненным иммунитетом после выздоровления. Поэтому данная модель является достаточно прогностической для инфекционных заболеваний, передающиеся от человека к человеку.
SEIR — производная SIR с 4 группами: S, E, I и R.
- S — число восприимчивых к инфекции особей
- E – особи в стадии инкубационного периода патогена
- I — инфицированные особи
- R — выздоровевшие или умершие.
SEIR отличается от SIR наличием «латентного периода». В течение латентного (инкубационного периода) люди инфицированы, но не являются зараженными из-за инкубационного периода патогена.
Для высокой точности прогнозирования требуется учитывать множество изменяющихся параметров:
- скорость инфицирования
- индекс репродукции
- скорость выздоровления
- изменяющиеся параметры карантинных ограничений и т.д.
На данный момент считается, что переболев коронавирусом covid-19 у человека вырабатывается иммунитет к повторному заражению. Однако если устойчивость к вирусу непостоянна, модель SIR преобразуется в SIS. Прогнозы на Коронавирус Хаб не учитывают возможность повторного заражения той же особью. Так же не учитывается вакцинация, дающая коллективный иммунитет обходя стадию массового заражения (вакцины пока нет).
На чем основаны решения
Для принятия решений применяют ряд метрик, например, время достижения пика эпидемического процесса. Пик может быть ярко выраженным, как мы наблюдали в Китае, с «плато» на вершине или одним или более кратером, где эпидемический процесс сначала затухает, а потом возобновляется, вновь проходя второй пик. Однако не все так просто.
«Пик обычно определяется по зарегистрированным случаям заболеваний и таким образом существенно отстает от реального пика новых заражений. Для понимания пика заражений необходимо учитывать, что от заражения до регистрации проходит инкубационный период — пять дней, время до обращения после проявления симптомов, время до получения результатов диагностики и регистрации случая. Это время, по данным COVID-19 Surveillance Group, на основе анализа 6801 случая для вспышки в Италии составляло 0-20 дней, а в среднем — четыре дня», — говорит Сергей Куликовский, генеральный директор и эксперт по аналитике больших данных компании «Полиматика».
Вторая важная метрика — пиковая нагрузка на лечебные организации. И здесь пик госпитализаций, наоборот, отстает от пика регистраций случаев заболеваний. По данным COVID-19 Surveillance Group, госпитализация отстает от регистрации на один день
Еще более важно учитывать нагрузку на реанимационную — наиболее дефицитную часть лечебных организаций. Этот пик еще больше отстает от пика регистраций и даже если пик регистрации уже пройден — поток пациентов в реанимационные отделения продолжает нарастать
Пик смертей отстает от пика регистрации примерно на десять дней.
«В большинстве стран, включая Россию, произошел экспоненциальный, взрывной рост количеств случаев в начале пандемии COVID-19. В России в отдельные периоды заболеваемость удваивалась каждые три дня. Экспоненциальный рост не интуитивен. Мало кто осознает, что могло произойти, если бы общество не предприняло никаких действий против развития пандемии. При сохранении динамики удвоения каждые три дня в России на 40-й день после 200-го случая у нас было бы примерно в 20 раз больше случаев. То есть примерно 1,26% населения оказалось бы зараженным. После этого не понадобилось бы и 20 дней для того, чтобы заражению подверглось практически все население страны, » — уверен Сергей Куликовский.
Существует простой математический прием, который позволяет решить проблему неинтуитивности экспоненциального роста при отображении данных, и которую использовали в качестве основы все страны — логарифмическая шкала представления количества случаев заражения. В таком виде удвоение каждые три, пять или одиннадцать дней представляют собой прямую, которую можно легко визуально продлить чтобы спрогнозировать, сколько случаев добавится в следующие несколько дней. На логарифмической шкале хорошо видна запоздалая на несколько дней реакция тренда заболеваемости на ужесточение или ослабление карантинных мер. При наличии достоверных данных можно сравнить страны или регионы — кто остановил распространение пандемии или потерял контроль. Но логарифмическая шкала не дает ответа на вопрос, что произойдет в среднесрочном будущем. Для прогнозирования используют специальные математические эпидемиологические модели.
Как пользоваться прогнозами
На каждом из 6 графиков прогнозирования отображается верхняя граница – наихудший сценарий, нижняя граница – наилучший, штрихпунктирная — аппроксимированная усредненная линия.
Прогноз сбудется в коридоре границ, достигая пиков и провалов между крайними границами. При успешном стечении обстоятельств развития эпидемии данные будут стремиться к нижней границе.
При расчетах учитывается кол-во тестирований в популяции и базовый индекс репродукции R0, что позволяет прогнозировать реальное кол-во инфицированных и погибших, а не только протестированных.
К каждому графику имеется подробное описание.
Вызывают сомнения
Подход команды из СПбГУ интересный, но их расчеты вызывают сомнения, отметил директор по исследованиям агентства Data Insight Борис Овчинников.
— Официальные данные не годятся для использования в прогнозировании реальной динамики эпидемии или для надежного сравнения разных стран между собой, — заявил он «Известиям». — Если же говорить о разных странах, почти наверняка мы придем к выводу, что универсальных законов развития эпидемии не существует. Скорость и длительность подъема, резкость перехода к спаду, глубина снижения, интервал между двумя волнами могут очень сильно варьироваться. И мы это видим по России — время начала нынешней волны в регионе не зависит от того, когда в регионе была первая волна. Да и сам характер этой волны в разных регионах разный — где-то резкий, но относительно короткий всплеск, а где-то долгий подъем с временными паузами и даже отступлениями.
Дать собственный прогноз развития ситуации в РФ эксперт затруднился. А вот доцент физического факультета МГУ им. М.В. Ломоносова Михаил Тамм отметил высокую математическую квалификацию авторов модели. Однако некоторые ее детали, по его мнению, «выглядят сомнительно».
Математика пандемии
 Фото: РИА Новости/Алексей Сухоруков
Фото: РИА Новости/Алексей Сухоруков
— В качестве стран, по образу и подобию которых идет моделирование, авторы работы используют государства Западной Европы — Францию, Испанию, Италию и Великобританию. У них другая специфика, — считает он. — По сравнению с весенним пиком у них летальность снизилась, а в России, наоборот, повысилась. Это связано с тем, что у них выросла выявляемость случаев COVID-19 относительно марта-апреля. Например, в Италии в марте умирало почти 15% заболевших. В России летальность тогда была менее 1%.
Кроме того, в последние полтора месяца Италия, Испания, Франция и Великобритании фактически вернулись к карантину, отметил эксперт. В России же о повторном локдауне речь, как известно, не идет.
Описание расчетной модели СПбГУ и первые результаты ее работы опубликованы в международном журнале Mathematics. Результаты анализа динамики и прогнозов представлены в разделе Центра интеллектуальной логистики сайта университета.
Модели прогнозирования
Первая модель была разработана в 1927 году, но до сих пор у департаментов здравоохранения во всем мире нет единого подхода к их использованию. В России в сибирском отделении РАН для моделирования эпидемии коронавируса используют одну модель — SEIR-HCD. А вот на сайте Министерства здравоохранения РФ какая-либо информация по прогнозированию отсутствует. «Строить прогнозы — самое неблагодарное занятие. В мире за несколько столетий прошло множество вспышек особо опасных заболеваний. Человечество научилось бороться с инфекцией», — объясняет факт отсутствия прогнозов главный инфекционист Минздрава России доктор медицинских наук Елена Малинникова.
В отличие от российских коллег, Центры по контролю и профилактике заболеваний Министерства здравоохранения и социальных служб США рассматривают 24 модели прогнозирования и считают, что прогнозы смертности и вероятного тренда в ближайшие недели помогают информировать общественное здравоохранение для принятия решений.
Результаты большого пула моделей интегрируют в один график для понимания диапазона динамики развития ситуации.
Фото: Центры по контролю и профилактике заболеваний Министерства здравоохранения и социальных служб США
Фото: Центры по контролю и профилактике заболеваний Министерства здравоохранения и социальных служб США
Эти прогнозы показывают совокупное число зарегистрированных случаев COVID-19 с февраля и прогнозируемых случаев смерти в течение следующих четырех недель в Соединенных Штатах.
Подписывайтесь на Telegram-канал РБК Тренды и будьте в курсе актуальных тенденций и прогнозов о будущем технологий, эко-номики, образования и инноваций.
Иллюзия достоверности
Большинство отчетов и графиков дают обобщенное суммирование данных — количество новых зараженных и умерших — и показывают ориентировочную динамику, основанную на недостоверных цифрах.
«Основные причины недостоверности данных: отсутствие массового тестирования во всех странах, многие инфицированные люди болели бессимптомно и никогда не узнают, что были больны. Эти неопределенности загрязняют многие метрики. Например, вы не можете точно рассчитать уровень смертности без показателя заболеваемости. Эпидемиологические модели недостоверны без этой информации, и это усложняет понимание серьезности распространения», — уверен Уилл Чейс, специалист по анализу данных и визуализации в Медицинском колледже Перельман, Университета Пенсильвании.